Wow. Almost 5 months between posts. I've been so busy on my projects that I have no time to write about them anymore. :)
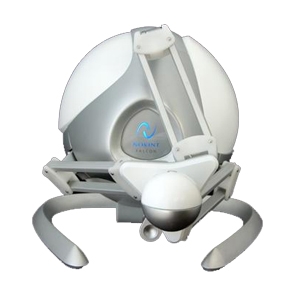
First off, libnifalcon, the open source driver for the Novint Falcon, is currently in alpha stage for the v1 release, soon to move to beta after a few more bugs are fixed. It's already seeing some usage, too!
The video above is a demo of a couple of patches for PureData written by Edgar Berdahl for use in Physical Interaction Design for Music class at the Center for Computer Research in Music and Acoustics at Stanford University. The video shows a haptic simulation of a bowed instrument, as well as a training patch for drum rolls. Moving toward the line in the middle of the window causes the falcon to kick back slightly, and the user must hold the end effector steady to keep the sound steady and constant. All of this is running on a beta version of the np_nifalcon external for max and pd, which is available on the libnifalcon site.
Next up is another project that I decided to throw together today to check out the OpenSoundControl protocol.
This is the Kitelight system controlled using the mrmr OSC interface builder for the iPhone. It's connecting to laptop running python using liblo and pyliblo for OSC controls. This goes through a xbee dev kit board to an arduino with xbee shield which is controlling a panel of RGB LEDs attached to the kite.
Usable range on the zigbee is ~100m, more than enough room for flyer to kite communications. Now that this works, I can also run lighting commands from PureData to do music synchonization or whatever else I might think of.
For all the URLs listed above, this project came together rather quick, about 90 minutes from start to finish, though obviously all the boards were already built, so it was just a matter of coding it all and learning OSC and mrmr.
Now, back to working on getting libnifalcon released...